In the Wake of Scala Days 2015
Scala Days Amsterdam conference was full of interesting topics so in this post I’ll cover talks on the Scala platform, core concepts for making Scala code more idiomatic, monad transformers, consistency in distributed systems, distributed domain driven design, and a little more.
This post came out of the post-conference presentation to my team, so the slides are also available here and contain all the links to related materials and presentations so you can discover more on your own.
Main themes #
So here are the main themes/areas discussed at Scala Days:
- Reactive Applications - a big topic around non-blocking design with reference to Reactive Streams and Akka
- Big Data/Fast Data - mainly focused on frameworks and architectures like Spark, GraphX, Kafka
- Functional Programming in Scala - topic related functional programming aspects in Scala which mainly covers Scalaz use cases and how-to’s
- Scala in practice - notes from production projects experience
- Distributed Systems - a broad topic focused on building systems with inter-node communication like Akka cluster or cluster management with Mesos
Scala keynote #
The talk is available at Parleys, here’re some highlights:
- A reactive platform is started to form (like JEE). If you check out the Typesafe website there’re a lot of frameworks forming a full stack for application development: DB access with Slick, concurrency/distributed interaction with Akka, Play as a web framework.
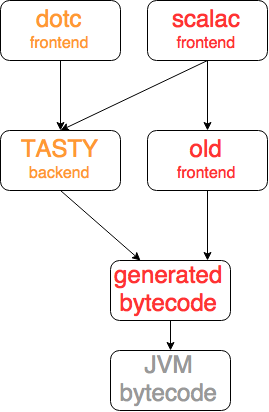
- Scala-specific platform with TASTY (Serialized Typed Abstract Syntax Trees)
- DOTC compiler (was close to completion at the moment of the talk)
- Type unions (U&T and U|T) - instead of
withmixin trait composition - Implicits that compose (implicit function types)
- Moving towards more pure functional programming
TASTY #
Java code compilation is bound to JVM, and Scala compiler adds Scala-specific signatures to classifiers that result in a larger size of classifiers and lower effectiveness.
Another problem that Scala faces is its dependency on JDK/JVM and its need to adapt to version changes (e.g. migrating from Java 7 to Java 8). Besides that JVM is not only one target platform, so that’s the place where TASTY comes into play. The main goal is in removing this dependency on specific platform versions. Plus some internal optimizations of code representation aimed to make code faster.
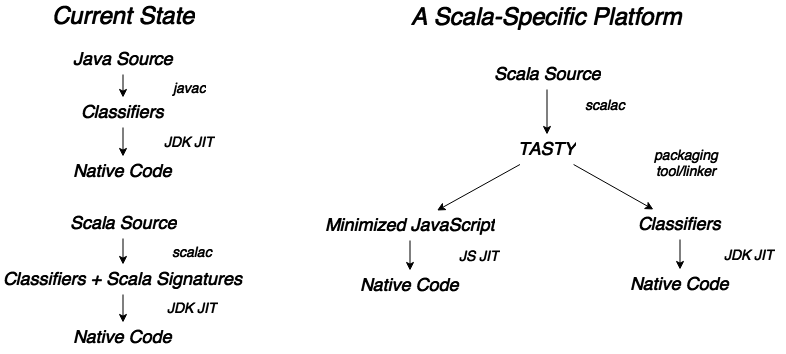
#####DOTC
The long-term plan for the Scala platform is in switching to a new Scala-specific DOTC compiler (based on Dependent Object Types calculus) and switch to work in conjunction with TASTY. For the moment of writing the compiler was close to completion, so for more details about DOTC here’s the link to the original paper Dependent Object Types: Towards a foundation for Scala’s type system.
Life beyond the illusion of the present #
A philosophical talk by Jonas Bonér focused on consistency in distributed systems. One of the main ideas was that actually data shouldn’t be updated or deleted, it can only be created and read(CRUD). And there’s still a number of problems in achieving consistency in distributed systems, but there’s a number of approaches to manage it though, like vector clocks, consistency as logical monotonicity (CALM), and commutative replicated data types (CRDTs). Here goes a brief description of them:
Vector clocks is an algorithm for generating a partial ordering of events in a distributed system and detecting causality violations
a block of code is logically monotonic if it satisfies a simple property: adding things to the input can only increase the output. By contrast, non-monotonic code may need to “retract” a previous output if more is added to its input.
Conflict-free replicated data type:
is a type of specially designed data structure used to achieve strong eventual consistency and monotonicity (absence of rollbacks). There are two alternative routes to ensuring strong eventual consistency: operation-based CRDTs and state-based CRDTs. The two alternatives are equivalent, as one can emulate the other, but operation-based CRDTs require additional guarantees from the communication middleware
Here’s a link to original CRDT paper and here’s a really good post on CRDTs by Jordan Rule
Lambda Architecture with Spark Streaming, Kafka, Cassandra #
It was mainly a pitch-talk about Kafka-Spark-Cassandra-based architectures (link to Parleys). What’s interesting here is that it looks like a common pattern: using Spark Streaming as an intermediate between Kafka and Cassandra for data ingestion. There’re a lot of talks arise lately on the subject of moving from Hadoop to Kafka-Spark-Cassandra-based architectures.
What about the talk itself, it was mainly describing these systems and providing some code samples. Reference application (killrweather) using all these technologies is available on github as well. Helena Edelson demonstrated “her nerdy chart” with different architecture design strategies and technologies suitable for them:
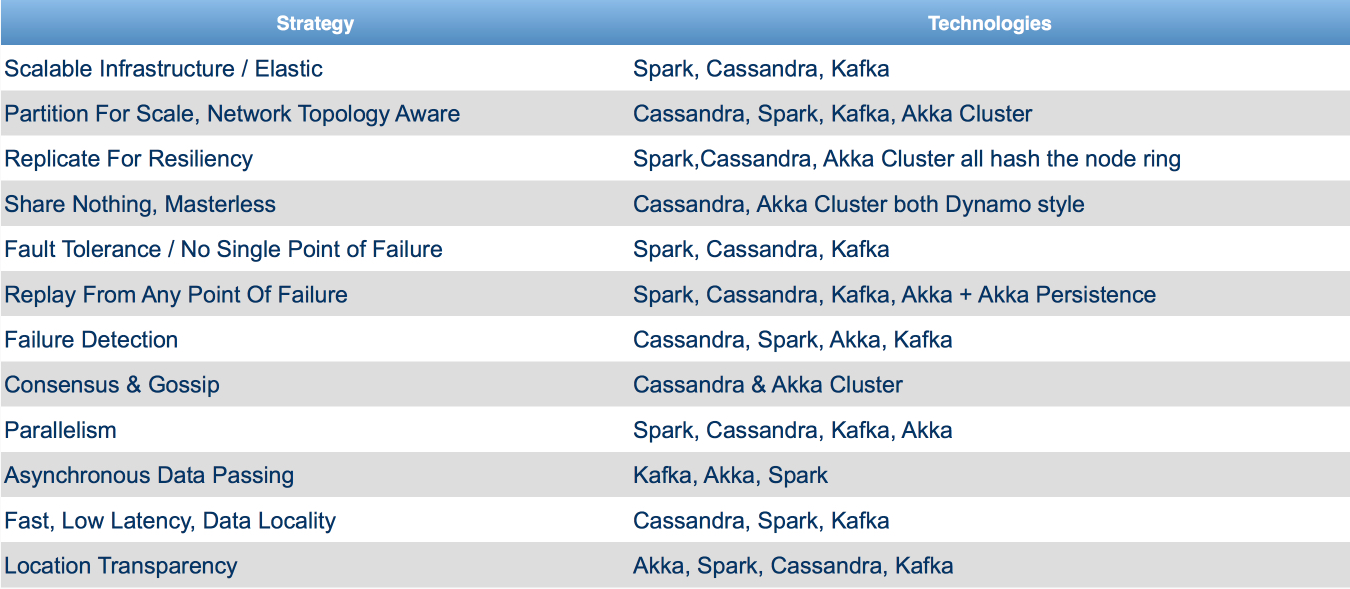
Another interesting part was that DataStax is developing a Cassandra Streaming driver which uses Cassandra as a source and is supposed to be used with Spark.
How to unsuck your Options in Futures #
Link to the video. Very often you need to unwrap the option value contained in the Future or any other container. This involves writing cumbersome code for extracting the actual value and this cumbersome code grows linearly. But Scalaz library provides a set of monads which are called “monad transformers” and allow you to unwrap one-level depth values to perform operations with them which results in a single type class/container of expected type in the end.
def f1: Future[Option[Int]] = ???
def f2: Future[Option[Int]] = ???
def f3: Future[Option[Int]] = ???
val result = for{
a <- OptionT(f1)
b <- OptionT(f2)
c <- OptionT(f3)
} yield a + b + c
val finOption: Future[Option[Int]] = result.run
Let’s imagine you have different containers and want to perform some operation on their values. For this case, you need to “cast” (wrap) the given objects to the closest one and then apply the monad transformer.
def f1: Future[String \/ Int] = ???
def f2: Option[Int] = ???
def f3: Future[Int] = ???
val result = for{
a <- EitherT(f1)
b <- EitherT(Future(f2 \/> "B is missing"))
c <- EitherT(f3.map(v => \/.right(v))
} yield a + b + c
val finEither: Future[String \/ Int] = result.run
And here’s how it can look like if we implement it ourselves
case class FutureOption[A](contents: Future[Option[A]]){
def flatMap[B](fn: A => FutureOption[B]) = FutureOption{
contents.flatMap{
case Some(value) => fn(value).contents
case None => Future.successful(None)
}
}
def map[B](fn: A => B) = FutureOption{
contents.map{ option =>
option.map(fn)
}
}
}
So why is all this needed? For-comprehensions are a really awesome feature actually which allows writing really concise and readable code. For-comprehensions basically use two operations that should be implemented in used classes: map and flatMap.
So here we go closer to the Monad. Apart from Category Theory, monad can be thought of as a TypeClass with methods: map, flatMap and create (bind and unit). And to satisfy the for-comprehension contract with our Future-of-Option monad transformer we need to implement map and flatMap.
Scalaz provides a number of useful monad transformers out of the box. But if you need anything special, you can generalize the given code a bit and use a Monad trait from Scalaz to abstract a bit more.
Understanding the backend of Big Data #
The talk was generally about four main topics:
-
the complexity of building distributed systems and how Functional Programming helps to reduce it. Basically, FP is good at transforming immutable data and forces immutable data structures leading to fewer errors in runtime and providing some sort of compile-time “correctness” checks upfront
-
cluster management is hard, with static resource allocation cluster resources are used for about 5-10% nowadays because of over-provisioning for handling load spikes. Mixed workloads are the most complex ones to estimate resources.
-
so here comes Mesos which provides dynamic resource allocation and management. And the main components of the ecosystem covered in the talk were Mesos itself, Marathon for scheduling long-running tasks, and Myriad which is the Mesos-YARN bridge
-
finally DCOS GA was released a couple of hours before the talk and it looks really promising, providing central DC management UI and console allowing to easily install Mesos frameworks. It’s available for free for Amazon and has a trial version for commodity hardware. It’s worth checking it out.
Essential Scala #
Really impressive talk by Noel Welsh providing several really simple guidelines to make Scala code better structured and more idiomatic which is crucial when someone just started using Scala or just needs to train the team moving to it. So basically six core concepts form the learning curve of Scala:
- Expressions, types, & values
- Objects and classes
- Algebraic data types
- Structural recursion
- Sequencing computation
- Type classes
Topics covered in the talk were ADT, Structural recursion, and Sequencing computation
Algebraic Data Types #
- Goal: translate data description into code
- Model data with logical ORs and ANDs
- Two patterns: product types(ANDs) and sum types(ORs)
- Sum and product together make algebraic data types
//product type: A has a B and C
final case class A(b: B, c: C)
//sum type: A is a B or C
sealed trait A
final case class B() extends A
final case class C() extends A
//Example: a Calculation either successful and has value or failed and has an error
sealed trait Calculation
final case class Success(value: Int) extends Calculation
final case class Failure(msg: String) extends Calculation
Structural recursion #
- Goal: transform algebraic data type
- Two patterns here: pattern-matching & polymorphism
Structural induction is a proof method that is used in mathematical logic, computer science, graph theory, and some other mathematical fields. It is a generalization of mathematical induction over natural numbers and can be further generalized to arbitrary Noetherian induction. Structural recursion is a recursion method bearing the same relationship to structural induction as ordinary recursion bears to ordinary mathematical induction.
//pattern matching
sealed trait A {
def doSomething: H = {
this match {
case B(d, e) => doB(d, e)
case C(f, g) => doC(f, g)
}
}
}
final case class B(d: D, e: E) extends A
final case class C(f: F, g: G) extends A
//polymorphism
sealed trait A {
def doSomething: H
}
final case class B(d: D, e: E) extends A {
def doSomething: H = doB(d, e)
}
final case class C(f: F, g: G) extends A {
def doSomething: H = doC(f, g)
}
- The processing algebraic data types immediately follows from the structure of the data
- Can choose between pattern matching and polymorphism
- Pattern matching (within the base trait) is usually preferred
Sequencing Computations #
- Goal: patterns for sequencing computations
- Functional programming is about transforming values … without introducing side-effects
- A => B => C
- Three patterns: fold, map, and flatMap
- Fold is abstraction over structural recursion
So here’s how we’d go with our own fold implementation
//initial version
sealed trait A {
def doSomething: H = {
this match {
case B(d, e) => doB(d, e)
case C(f, g) => doC(f, g)
}
}
}
final case class B(d: D, e: E) extends A
final case class C(f: F, g: G) extends A
//first refactoring
sealed trait A {
def fold(doB: (D, E) => H, doC: (F, G) => H): H = {
this match {
case B(d, e) => doB(d, e)
case C(f, g) => doC(f, g)
}
}
}
final case class B(d: D, e: E) extends A
final case class C(f: F, g: G) extends A
//final result
sealed trait Result[A] {
def fold[B](s: A => B, f: B): B =
this match {
case Success(v) => s(v)
case Failure() => f
}
}
final case class Success[A](value: A) extends Result[A]
final case class Failure[A]() extends Result[A]
- fold is a generic transform for any algebraic data type
- but it’s not always the best choice
- not all data is an algebraic data type
- there’re other methods easier to use (
mapandflatMap)
So main conclusions of the talk are that in fact, Scala is simple, 3 described patterns cover 90% of code (and 4 cover 99%) and that program design in Scala is systematic.
A Purely Functional Approach to Building Large Applications #
It was a really monadic talk about Scalaz usage in real projects showing how to properly abstract the logic with monads and wiring functions together.
- Reader monad: in simple words, it’s a wrapper providing context for functions that need it. Generally speaking, the scope where such kind of dependency injection is needed is function scope, so here comes the reader that provides the context to the function.
- ReaderT is a monad transformer like we’ve seen before which unwraps the values which sit in some monad container like Option or Future
- Kleisli arrow: is a base abstraction for ReaderT and is really handy when it comes to the composition of monadic functions, it’s simply a wrapper for a function of type
A => F[B]. - Task monad: a substitute for Scala Future, differs in that sense that occupies thread only at the moment of materialization, which allows performing different transformations lazily lowering the amount of context switching
Easy Scalable Akka Applications #
The talk was focused on distributed domain-driven design and its implementation with Akka.
Two main approaches discussed were CQRS and Event Sourcing:
-
Command Query Responsibility Segregation
CQRS at its heart is the notion that you can use a different model to update information than the model you use to read information.
-
Event Sourcing
Event Sourcing ensures that all changes to the application state are stored as a sequence of events. Not just can we query these events, we can also use the event log to reconstruct past states, and as a foundation to automatically adjust the state to cope with retroactive changes.
A couple of words on the distributed domain-driven design. Some examples of Non-Distributed Domain
- Basic CRUD (Create, Read, Update, Delete)
- Writes and reads to same database (ACID)
- Scaled via multiple identical replicas
- Bottlenecks on contention (reads and writes interfere with each other)
With Akka and DDDD
- Wouldn’t it be great if you could just keep your domain instances in memory?
- But how to recover from its volatile nature: an event journal!
So the main idea here is to use Actors to represent domain entities (e.g. bank accounts) and store the state mutations as a commit log with periodical snapshots which is achieved with an akka-persistence module. Cassandra was used for storing the journal so in total the system looks really interesting. CRUD and CQRS were compared and tested with the Gatling stress tool with results available in Boldradius blog post.
Some Other Cool Talks #
- Spores: type-safe function serialization for remote method invocation. Imagine actors passing functions instead of functions+data, immutable data enforced
- Project Gålbma: Actors vs. Types - so generally the main goal of this project is to provide typed ActorRefs, in future remove Actor trait and switch to more pure actor model enforcing message-passing behavior
- The talk about using Finagle in SoundCloud was pretty interesting. Finagle is a high-performance RPC server supporting various protocols, built on Netty, and enforcing functional programming in API. It is really nice and easy-to-use to build a distributed system.
- Scala.js talk was pretty interesting in terms of compiler implementation details and it seems that it is mature enough
- Reactive streams topic was pretty interesting especially in terms of back pressure and constructing the data flows model.
Wrapping Up #
- Scala language becomes more and more stable in terms of API changes and moves towards improving performance, being more functionally pure as well as growing its own platform
- Scala is widely used as an implementation language in major and emerging distributed data processing/computing frameworks (Akka, Spark, Crunch)
- Scalaz is used in a wide variety of projects for proper abstractions or just for making code more concise and reusable (/, monad transformers)
- There’re a lot of Scala libraries/frameworks forming mature ecosystem (e.g. Akka and Play) which can be used for building large distributed applications
More awesome slides and videos from Scala Days Amsterdam are available at Parleys!