Resource Allocation in Mesos: Dominant Resource Fairness
Apache Mesos provides a unique approach to cluster resource management called two-level scheduling: instead of storing information about available cluster resources in a centralized manner it operates with a notion of resource offers which slave nodes advertise to running frameworks via Mesos master, thus keeping the whole system architecture concise and scalable. Master’s allocation module is responsible for making the decisions about which application should receive the next resource offer and it relies on Dominant Resource Fairness(DRF) algorithm for making these decisions. This post presents a set of experiments for different use cases using simple Mesos framework implementation to observe and analyze DRF behavior.
Architecture Recap #
Mesos official documentation provides a great overview of the architecture, so let’s briefly recap the framework and resource offers part of it.
Frameworks #
Mesos frameworks consist of two main components: Scheduler and Executor.
The Scheduler is a single instance/process which negotiates with the Master and is responsible for handling resource offers, task submissions, tasks status updates, framework messages, and exceptional situations such as slave losses, disconnections, and various errors. Sometimes high availability is a requirement for schedulers, so some sort of leader election or specific logic is needed to avoid conflicts in task submissions.
The Executor is a process executed on Slave nodes that receive tasks from Scheduler and run them. Executor lifecycle is bound to Scheduler so when Scheduler finished its job it also shutdowns the executors (actually Mesos master performs this routine when framework terminates). If the Executor is a JVM process it usually has a thread pool for executing received tasks.
Tasks are serialized in protobuf and contain all the information about resources needed, executor to run on, some binary serialized payload (e.g. Spark tasks are serialized and transferred as a payload in Mesos tasks). Here’s an example of how Task is created:
def buildTask(offer: Offer, cpus: Double, memory: Int, executorInfo: ExecutorInfo) = {
val cpuResource = Resource.newBuilder
.setType(SCALAR)
.setName("cpus")
.setScalar(Scalar.newBuilder.setValue(cpus))
.setRole("*")
.build
val memResource = Resource.newBuilder
.setType(SCALAR)
.setName("mem")
.setScalar(Scalar.newBuilder.setValue(memory))
.setRole("*")
.build
TaskInfo.newBuilder()
.setSlaveId(SlaveID.newBuilder().setValue(offer.getSlaveId.getValue).build())
.setTaskId(TaskID.newBuilder().setValue(s"$uuid"))
.setExecutor(executorInfo)
.setName(UUID.randomUUID().toString)
.addResources(cpuResource)
.addResources(memResource)
.build()
}
def buildExecutorInfo(d: SchedulerDriver, prefix: String): ExecutorInfo = {
val scriptPath = System.getProperty("executor.path","/throttle/throttle-executor.sh")
ExecutorInfo.newBuilder()
.setCommand(CommandInfo.newBuilder().setValue("/bin/sh "+scriptPath))
.setExecutorId(ExecutorID.newBuilder().setValue(s"${prefix}_$uuid"))
.build()
}
Sources are available at the accompanying github repo.
Resource Offers #
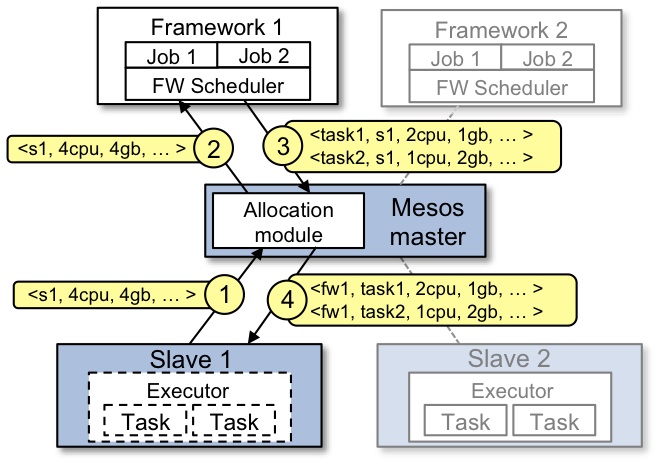
- Slave nodes periodically report to the Master free resources they can provide. This also happens when executor tasks complete minimizing delay
- Allocation module starts offering the resources to frameworks. A dominant resource fairness algorithm is used to define the order in which frameworks are offered the resource. The framework can either accept or decline the offer depending on its demand. In case of decline (e.g. insufficient resources of some type) the resources are offered to the next framework according to DRF.
- If resources in the offer satisfy the framework’s demand then it creates a list of Tasks and sends it back to Master. Master could respond with an error if tasks resources exceed the amount provided in the offer.
- Master sends set of tasks to the Executor on the Slave (and launches the executor if it’s not running)
Dominant Resource Fairness (DRF) #
The main problem that DRF solves is sharing of the resources of multiple types (but not only CPU) which hasn’t been addressed before and caused insufficient resource distribution among applications with heterogeneous resource demands. To address this problem the notions of dominant share and dominant resource have been introduced.
Dominant resource - a resource of a specific type (cpu, memory, disk, ports) which is most demanded by the given framework among other resources it needs. This resource is identified as a share of the total cluster resources of the same type.
Example 1: given a cluster with the total amount of 10 CPUs and 20GB RAM, resource demands are: Framework A < 4 CPU, 5 GB >, Framework B < 2 CPU, 8 GB >. The same expressed as a share of total cluster resources: Framework A < 40% CPU, 25% RAM >, Framework B < 20% CPU, 40% RAM >. So for Framework A CPU is a dominant resource, while for Framework B RAM is.
DRF computes the share of dominant resource allocated to a framework (dominant share) and tries to maximize the smallest dominant share in the system. During the next round of resource offers allocation module applies DRF to identify the dominant shares of the frameworks and offers the resources first to the one with the smallest dominant share, then to the second smallest one, and so on.
Example 2: consider the cluster with total amount of 10 CPUs and 20GB RAM, resource demands are: Framework A < 3 CPU, 2 GB >, Framework B < 1 CPU, 5 GB >. Same in percents: A_< 33% CPU, 10% RAM >, B< 10% CPU, 25% RAM >_. Steps:
1. (10cpu, 20gb) to A: A(3cpu, 2gb, 33%), B (0cpu, 0gb, 0%)
2. ( 7cpu, 18gb) to B: A(4cpu, 5gb, 40%), B (1cpu, 5gb, 25%)
3. ( 6cpu, 13gb) to B: A(4cpu, 5gb, 40%), B (2cpu, 10gb, 50%)
4. ( 5cpu, 8gb) to A: A(6cpu, 4gb, 66%), B (2cpu, 10gb, 50%)
5. ( 2cpu, 6gb) to B: A(6cpu, 4gb, 66%), B (3cpu, 15gb, 75%)
6. ( 1cpu, 1gb) to A: A(6cpu, 4gb, 66%), B (3cpu, 15gb, 75%)
7. ( 1cpu, 1gb) to B: A(6cpu, 4gb, 66%), B (3cpu, 15gb, 75%)
... and so on until the task of one of the frameworks is finished and resources are released.
Let’s walk through the steps. The first resource offer goes to A (let’s say it was executed first, so it receives the offer first). A accepts the offer and its dominant share becomes 33%, so the next offer goes to the framework with the smallest dominant share which is B (step 2). After accepting the offer dominant share of B becomes 25% which is less than the share of A, so it receives the next offer (step 3) and now its share is 50%. A becomes the framework with the smallest share and receives the next offer (step 4) and so on.
In the end, there is only 1cpu and 1gb RAM available, so that cluster CPU is utilized for 90% and RAM for 95% which is pretty good saturation.
Hopefully, the description was not very complicated, because the algorithm itself is very simple and sound. Please refer to the original paper “Dominant Resource Fairness: Fair Allocation of Multiple Resource Types” for more details.
There’s not always that perfect cluster saturation in real life so the next part of the post will cover different use cases and how DRF addresses them. We’re about to run several instances of simple Mesos Framework with different resource demands (configured at launch time) in parallel to observe DRF behavior and identify potential bottlenecks.
Example Framework #
For the purpose of observation of DRF behavior a simple Mesos framework is going to be used. The scheduler will submit one task per resource offer round, and the executor will emulate the processing by putting the task thread on sleep for a random amount of time. The main requirement of the framework is configurable task resource demands to properly set up different conditions for parallel execution with heterogeneous resource demands.
Resource offers handling in the Scheduler code:
override def resourceOffers(driver: SchedulerDriver, offers: util.List[Offer]): Unit = {
for(offer <- offers){
stateLock.synchronized {
logger.info(s"Received resource offer: cpus:${getCpus(offer)} mem: ${getMemory(offer)}")
if(isOfferValid(offer)){
val executorInfo = executors.getOrElseUpdate(offer.getSlaveId.getValue, buildExecutorInfo(driver, "DRFDemoExecutor"))
//amount of tasks is calculated to fully use resources from the offer
val tasks = buildTasks(offer, config, executorInfo)
logger.info(s"Launching ${tasks.size} tasks on slave ${offer.getSlaveId.getValue}")
driver.launchTasks(List(offer.getId), tasks)
} else {
logger.info(s"Offer provides insufficient resources. Declining.")
driver.declineOffer(offer.getId)
}
}
}
}
def buildTasks(offer: Offer, config: Config, executorInfo: ExecutorInfo): List[TaskInfo] = {
val amount = Math.min(getCpus(offer)/config.cpus, getMemory(offer)/config.mem).toInt
(1 to amount).map(_ =>
buildTask(offer, config.cpus, config.mem, executorInfo)
).toList
}
An excerpt from the Executor task handling method:
override def launchTask(driver: ExecutorDriver, task: TaskInfo): Unit = {
threadPool.execute(new Runnable() {
override def run(): Unit = {
val taskStatus = TaskStatus.newBuilder().setTaskId(task.getTaskId)
val taskId = task.getTaskId.getValue
logger.info(s"Task $taskId received by executor: ${task.getExecutor.getExecutorId.getValue}")
driver.sendStatusUpdate(
taskStatus
.setState(TaskState.TASK_RUNNING)
.build()
)
val delay = 20000 + Random.nextInt(20000)
logger.info(s"Running task for ${delay/1000f} sec.")
Thread.sleep(delay)
val msg = s"Task $taskId finished"
logger.info(msg)
driver.sendStatusUpdate(
taskStatus
.setState(TaskState.TASK_FINISHED)
.setData(ByteString.copyFrom(serialize(msg)))
.build()
)
}
})
}
And the framework’s entrypoint looks like this:
case class Config(
mesosURL: String = "",
name: String = "",
cpus: Double = 0.1,
mem: Int = 512
)
...
def run(config: Config): Unit ={
val framework = FrameworkInfo.newBuilder
.setName(config.name)
.setUser("")
.setRole("*")
.setCheckpoint(false)
.setFailoverTimeout(0.0d)
.build()
val driver = new MesosSchedulerDriver(new DRFDemoScheduler(config), framework, config.mesosURL)
driver.run()
}
Full source code available on github.
The config case class is created with scopt (scala options parser) and the framework invocation code looks as follows:
java -cp /throttle/throttle-framework.jar \
-Dexecutor.path=/throttle/drf-executor.sh \
io.datastrophic.mesos.drf.DRFDemoFramework \
--mesos-master zk://zookeeper:2181/mesos \
--framework-name 'Framework A' \
--task-cpus 2 \
--task-memory 1000
This allows running the same framework code with different task resource demands to easily setup experimental use cases.
Experiments #
A small virtual cluster will be used for the experiment with a total capacity of 6 CPUs and 6.6 GB RAM. We’re going to use small-sized dummy tasks (which simply sleep to emulate processing) so the total capacity is not big deal here. A dockerized environment is also available on github.
Redistribution of resources between frameworks with same demands #
Let’s first look at how Mesos will redistribute resources when new frameworks with similar resource demands are added and removed from the cluster. We’re going to use < 0.5 CPU, 512 RAM > (or < 8% CPU, 7.5% RAM >) as task resource demands and 20000 + Random.nextInt(20000) millis as task duration to make tasks running for 20-40 seconds each because when tasks are too small the cluster will not be fully loaded (default resource offers round frequency is 5 seconds).
First Framework A will be launched as the only application running on the cluster. After a while we’ll see this picture in Mesos UI:

Let’s now launch competing Framework B. In most cases the behavior is as expected - equal sharing of resources:

But for short periods of time one can observe this picture (disregarding the framework):
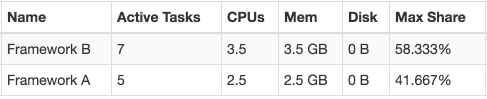
This is a result of the transitional situation when both frameworks have been having equal dominant share (50/50) and when two of Framework A’s tasks have finished close to each other in time (resulting in 4 running tasks). After that the first offer goes to A, it accepts and launches one task (now it’s 5 running tasks). The next offer goes to B and it accepts it (having no tasks finished up to the moment, the total amount of tasks is 7). The next offer will go to Framework A. It’s actually not an extraordinary situation though because these distortions are normal taking into account specifics of the framework implementations and how they work with resource offers.
Now Framework C is launched in the cluster:
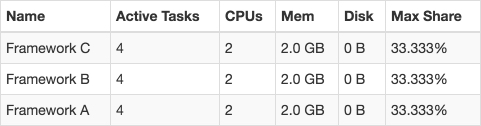
For the reasons described above sometimes a different picture can be observed:
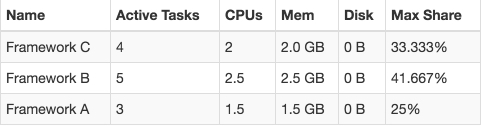
From this, we can conclude that if more frameworks are running in parallel then these discrepancies would be observed more often, but none of the frameworks will occupy the majority of the resources forever. DRF defines the priorities in which frameworks are offered the resources, but within a single round, none of the frameworks are offered resources twice. There exists Weighted DRF implementation which changes this behavior.
Redistribution of resources between frameworks with heterogeneous resource demands #
Now Framework A’s tasks will consume < 2 CPU, 1000 RAM > (or < 33% CPU, 15% RAM >) and Framework B’s tasks will consume < 1 CPU, 2000 RAM > (or < 16% CPU, 30% RAM >).
Let’s see how it works:

Looks awesome, but here’s a trick in resource demands: frameworks together completely saturate the cluster and their dominant resources are not in the conflict. Two tasks of Framework A use ~60% of cluster CPU while two tasks of Framework B use ~67% of memory. But let’s increase Framework B’s memory demands up to 36% (2500MB), so to run two tasks it will need >72% of the max share and more resources in the offer. Most of the time we’ll be observing this picture:

The picture could change when both tasks of Framework A are finished in between resource offer rounds and all freed resources are offered to Framework B which will launch two of its tasks. After that there are enough resources for launching only one task of Framework A :

The conclusion is that running multiple small tasks is better than launching large ones in terms of time spent waiting for enough resources to be freed by other frameworks.
Discussion #
After a number of simulations with a different number of frameworks with different dominant resources the observations described above still hold. Corner cases still appear but within different time frames, and resource allocations converge to a fair distribution of resources.
One important thing to note is that one resource offer represents the amount of resources available on one slave node. This means that if someone wants to execute a task that needs N cpus and M memory there should exist a physical node in the cluster which has this capacity.
Mesos enforces incremental task execution to run the whole job (fine-grained mode), but if some sort of gang scheduling is needed then the framework could implement a coarse-grained approach (like Spark does) to run its executors with maximum available resources and schedule the job by means of the framework. Another important thing to mention is that frameworks don’t have information about the total amount of cluster resources so it’s hardly possible to allocate all the resources at once.
DRF Properties #
The Dominant Resource Fairness algorithm satisfies several important properties which are worth mentioning to have a full picture. Cites are from the original paper “Dominant Resource Fairness: Fair Allocation of Multiple Resource Types”:
- Sharing incentive: Each user should be better off sharing the cluster, than exclusively using her own partition of the cluster. Consider a cluster with identical nodes and n users. Then a user should not be able to allocate more tasks in a cluster partition consisting of 1/n of all resources.
- Strategy-proofness: Users should not be able to benefit by lying about their resource demands. This provides incentive compatibility, as a user cannot improve her allocation by lying.
- Envy-freeness: A user should not prefer the allocation of another user. This property embodies the notion of fairness.
- Pareto efficiency: It should not be possible to increase the allocation of a user without decreasing the allocation of at least another user. This property is important as it leads to maximizing system utilization subject to satisfying the other properties.
- Single resource fairness: For a single resource, the solution should reduce to max-min fairness.
- Bottleneck fairness: If there is one resource that is percent-wise demanded most of by every user, then the solution should reduce to max-min fairness for that resource.
- Population monotonicity: When a user leaves the system and relinquishes her resources, none of the allocations of the remaining users should decrease.
- Resource monotonicity: If more resources are added to the system, none of the allocations of the existing users should decrease.
Rephrasing a sharing incentive point: users are offered to share the whole cluster resources instead of exclusively owning their own partition. While in both cases the user has guaranteed minimum allocation of 1/n of cluster resources (given that there’re n users) in case of partition allocation user will not be able to allocate more tasks than 1/n while with DRF it’s possible to allocate more tasks using resources released by other frameworks.
Where to go from here #
- The original Mesos paper: “Dominant Resource Fairness: Fair Allocation of Multiple Resource Types”
- Video of the DRF talk at USENIX Symposium on Networked Systems Design and Implementation
- Paper: Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
- Paper on Omega scheduler describing different from two-level scheduling approaches: Omega: flexible, scalable schedulers for large compute clusters
- Project code and dockerized environment to work with at github