Spark JobServer: from Spark Standalone to Mesos, Marathon and Docker
After several years of running Spark JobServer workloads, the need for better availability and multi-tenancy emerged across several projects author was involved in. This blog post covers design decisions made to provide higher availability and fault tolerance of JobServer installations, multi-tenancy for Spark workloads, scalability and failure recovery automation, and software choices made in order to reach these goals.
Spark JobServer #
Spark JobServer is widely used across a variety of reporting and aggregating systems. One of the valuable features among others is unified REST API to interact with Spark Contexts, execute jobs and retrieve results asynchronously from a cache. Unified API allows standardizing any Spark application and abstracts away the need for application developers to initialize and configure Spark Context every time a new application is developed.
In most of the cases, Spark applications are developed to be used with spark-submit which in turn will
create a context at the moment of execution. Context creation is a costly operation and takes time depending
on cluster utilization and resources requested. JobServer addresses this issue by maintaining long-running
contexts so any loaded application doesn’t have to wait for a context to be initialized which in turn results
in faster response and execution times and allows to use Spark applications as backends for querying data.
Originally, the JobServer was developed to run on Spark Standalone clusters and some of its design features address same problems as e.g. Application Master in YARN. This blog post is focused on design decisions targeted at increasing stability of the JobServer by utilizing Mesos as Spark cluster manager and Marathon as an orchestration system for providing high availability.
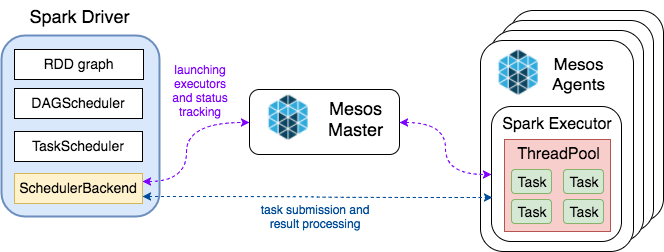
Spark uses a Cluster Manager for scheduling tasks to run in distributed mode (Figure 1). Supported cluster managers are Spark Standalone, Mesos and YARN. Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program)[source].
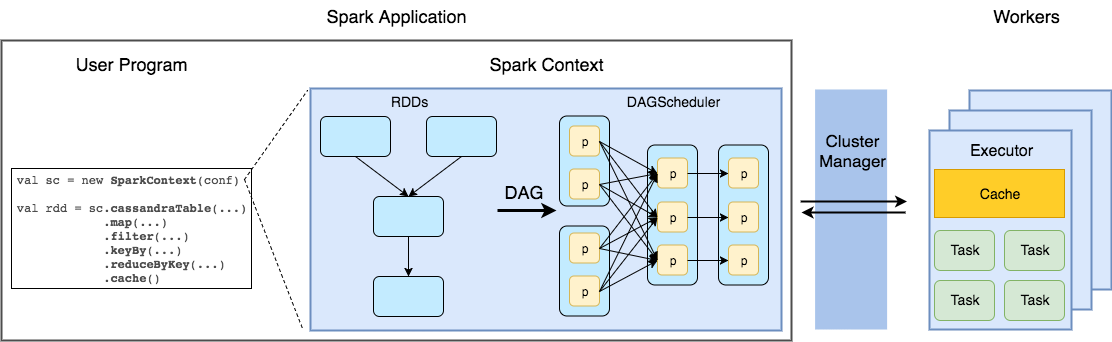
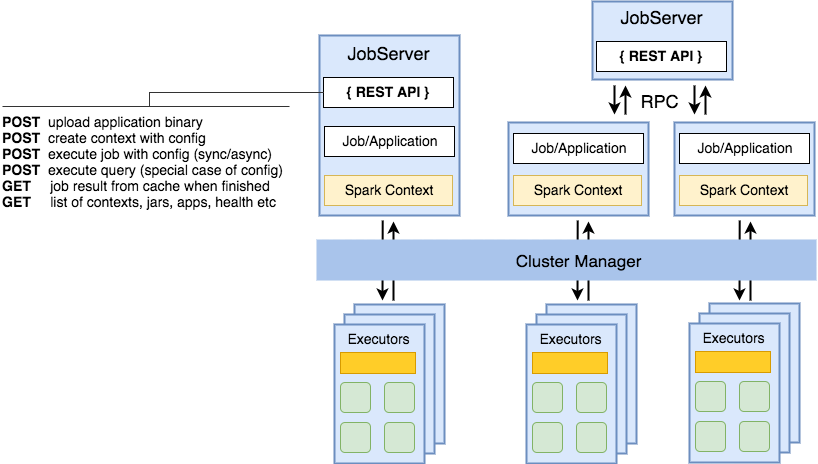
JobServer runs Spark Applications either being Spark Driver itself or spawning a separate JVM per
context thus being out-of-the-box compatible with supported Cluster Managers (Figure 2).
Limitations #
Spark Standalone as a cluster manager has several significant limitations making maintenance and operations harder for engineers:
- Spark master is a single point of failure when single instance is used. In situations when workers fail and/or restart they register back to Spark Master and a cluster continues its operations. However, when the master fails and/or restarts workers are unable to register automatically and whole cluster restart is needed. This problem can be solved by running Spark Master in HA mode and performing leader election and service discovery with ZooKeeper.
- Different Spark versions across applications. With growing number of Spark applications dependencies versions start to diverge and at some point, it’s hard to perform a big-bang upgrade and the need for different environments emerges. That is, applications using latter Spark major releases will need another cluster with the corresponding version when standalone mode is used and this situation is suboptimal: number of clusters, amount of hardware and engineering time needed for support will grow significantly.
- Heterogeneous environments and dependencies. Although multiple Spark versions could be considered as a special case of this problem it’s different and can arise even if same Spark version is used. Applications not only can depend on different third-party libraries (e.g. hadoop and/or file format families) but also be compiled with different Java versions (in case JVM languages are used). Managing classpaths and runtime class version conflicts (also known as ‘jar hell’) is a time-consuming task which is better to avoid by means of stronger isolation.
So let’s look at the requirements expected to be met by a cluster manager (Omega paper by Google can be used as a reference):
- Efficiency
- efficient sharing of resources across applications
- utilization of cluster resources in the most optimal manner
- Flexibility
- support of wide array of current and future frameworks
- dealing with hardware heterogeneity
- orchestration framework for applications providing high availability guarantees
- support of resource requests of different types (RAM, CPU, ports)
- Scalability
- scaling to clusters of hundreds of nodes
- scheduling system response times must remain acceptable while increasing number of machines and applications
- Robustness
- fault tolerance guarantees for the system and applications
- high availability of central scheduler component
While part of these requirements is met by YARN it won’t provide high availability guarantees for JobServer itself. Service failures can be addressed by means of systemd or upstart but a hardware failure will need a manual maintenance in most of the cases involving provisioning of a new machine if there’s no reserved one available and deployment of JobServer to it. Given that all these steps are automated with tools like Ansible or Chef the downtime for customer-facing applications is still unacceptable.
Another solution available in the open-source world is Apache Mesos. While it can be used as Spark cluster manager out of the box, it’s also possible to execute standalone applications as long-running cluster tasks by means of Marathon - a container orchestration platform for Mesos.
Mesos overview #
Mesos is a cluster resource manager which provides linear scalability, high availability and container support with a unique approach of two-level scheduling. Official documentation provides a detailed overview of Mesos architecture and its components, and here’s a really quick recap to be on the same page (Figure 3).
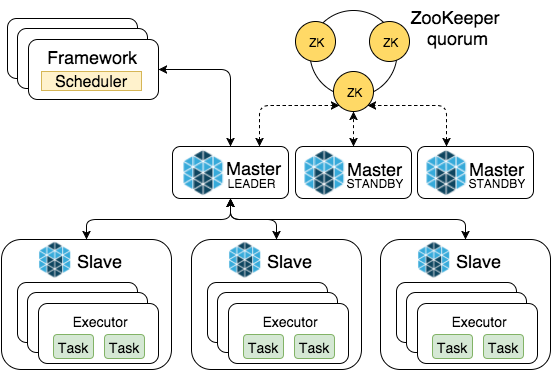
- Master
- a mediator between slave resources and frameworks
- enables fine-grained sharing of resources by making resource offers
- serves as master for Spark (not a single point of failure)
- Slave (Agent)
- manages resources on physical node and runs executors
- Framework
- application that solves a specific use case (e.g. Spark)
- Scheduler negotiates with master and handles resource offers
- Executors consume resources and run tasks on slaves
In Mesos terminology, Spark is a framework that acquires cluster resources to execute its jobs. Depending on job resource demands (RAM, CPU) Spark accepts or declines resource offers made by Mesos Master allocation module. Allocation module uses Dominant Resource Fairness algorithm which in simple words orders sending of offers to frameworks based on their cluster usage i.e. frameworks using fewer resources than the others will receive offers first. More details are available in Dominant Resource Fairness explained blog post.
Spark on Mesos #
Spark supports two modes of running on Mesos: fine-grained(deprecated) and coarse-grained. To understand the difference let’s have a quick look into Mesos scheduling algorithm (Figure 4).
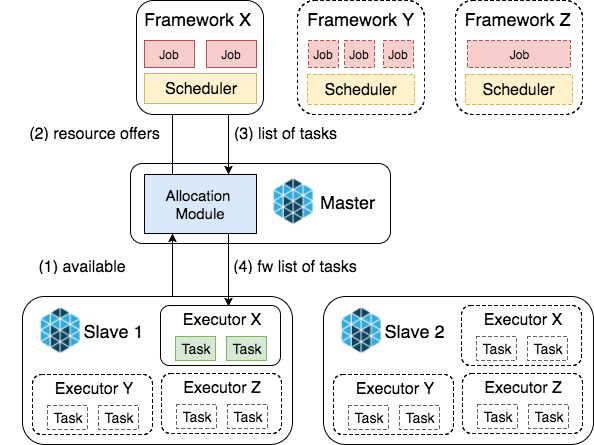
- Agent nodes continuously report to Master amount and type of available resources: RAM, CPU, disk, ports
- Allocation module starts offering resources to frameworks
Framework receives offers
- if resources do not satisfy its needs - rejects the offer
- if resources satisfy its demands - creates list of tasks and sends to master
- Master verifies tasks and forwards to executor (and launches the executor if it’s not running)
A task in Mesos terminology is a single unit of work executed by a framework. In fine-grained mode Spark wraps its every task in Mesos task thus relying on Mesos scheduling, while in coarse-grained mode Spark only runs its executors (Spark workers) and executes tasks relying on its own scheduler and RPC mechanism (Akka or Netty, depending on Spark version) for submitting tasks to executors (Figure 5)
Heterogeneity and multi-tenancy #
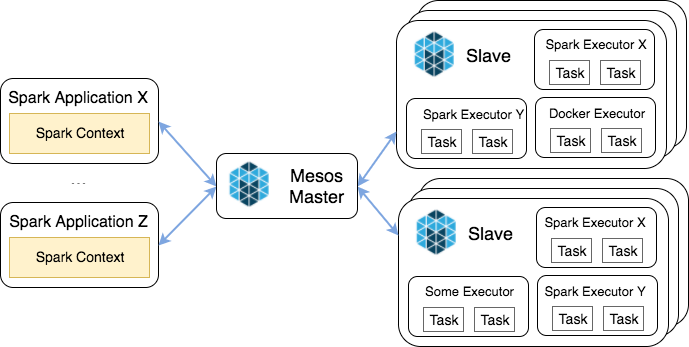
Moving from Spark Standalone to Mesos addresses yet another problem of shrinking down a number of clusters being used and providing a better cluster utilization. While it’s a valid point that it’s possible to run multiple contexts on the same cluster even with Spark Standalone, it becomes impossible to manage incompatible Spark versions within the same installation not to mention Java versions. With proper packaging and environment setup, it’s easy to achieve these goals with Mesos which makes it possible to not only run heterogeneous Spark contexts on the same cluster but share it with other applications as well (Figure 6).
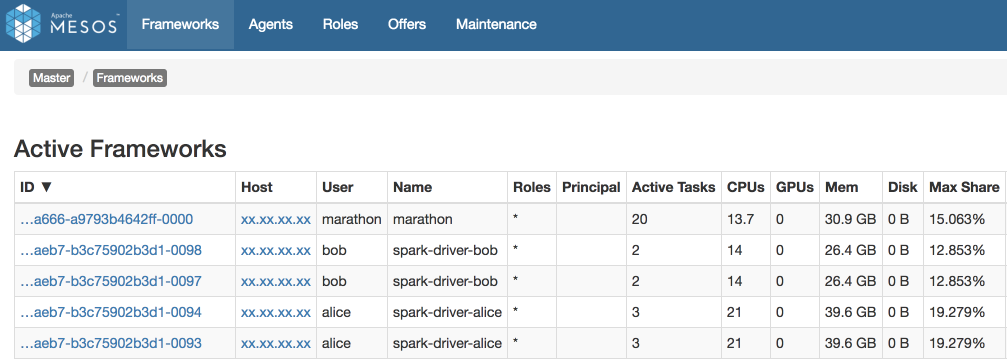
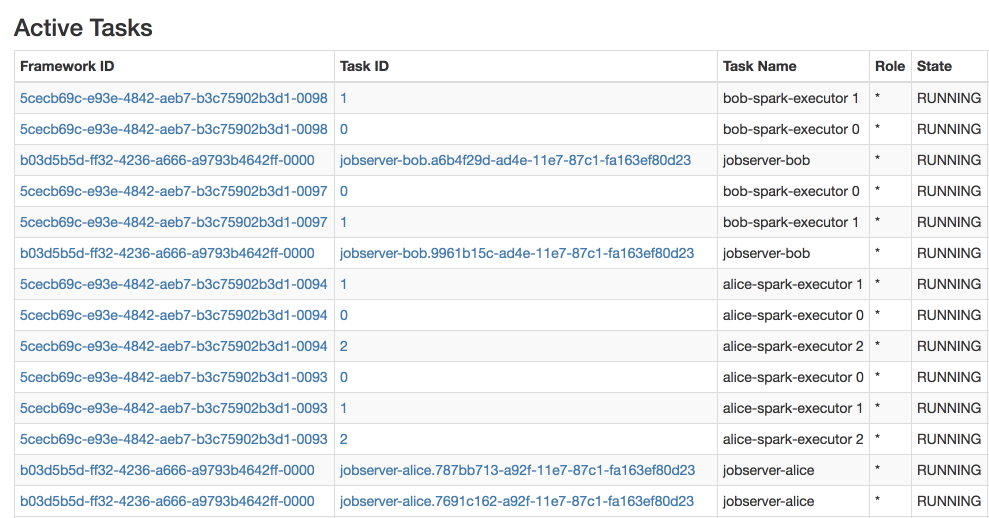
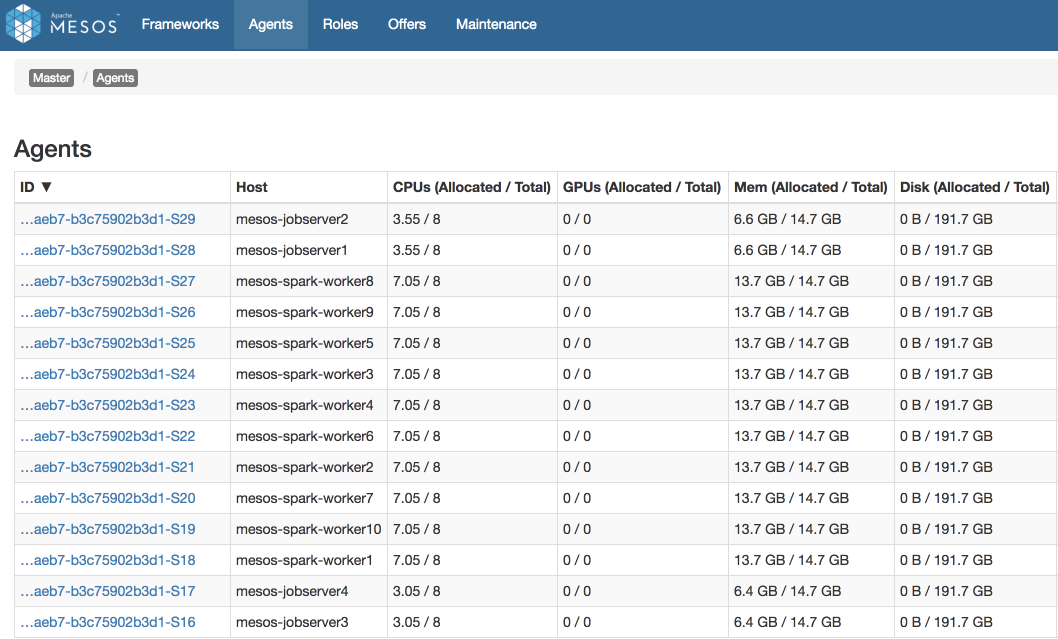
Let’s have a look at an example of running 4 Spark JobServer applications (jobserver-bob and jobserver-alice 2 instances each) on the same cluster. Each of JobServers creates Spark Context managed by driver program: spark-driver-bob with 14 CPU and spark-driver-alice with 21 CPU in total. Also, one can observe Marathon framework using 15% of cluster resources (Figure 7). Marathon is used to run JobServer instances which in turn use Mesos for running Spark Contexts. Details of running JobServer in Marathon will be covered in the next part of the blog post series.
A naive way for supporting multiple Spark (and Java) versions would be installing all the necessary binaries on every machine in a cluster. While this allows to ramp up really quickly, usually after not so long time environments start to diverge and maintenance becomes tricky.
The good news is that Spark-Mesos integration supports Docker: spark.mesos.executor.docker.image configuration parameter allows specifying a custom Docker image to use as an executor. Although it doesn’t look like the most important thing it provides a great flexibility when a number of environments and software versions being used grows.
Yet another important feature worth mentioning is Dynamic Resource Allocation which allows Spark to return unused resources to a cluster manager and acquire more resource when application demands grow. This provides a better resource utilization in case of multi-tenant workloads but it should be used with caution in case of latency-critical applications because resource acquisition takes some time and in worst case, some other framework can use requested resources. Dynamic allocation is supported for any Spark cluster manager using coarse-grained mode and in Mesos it’s a responsibility of an engineer to run Spark External Shuffle service in order to make it work.
Conclusion #
With a minor tweaking of existing Spark jobs and Spark JobServer, it’s become possible to achieve better utilization of a single cluster instead of running multiple idling Standalone clusters (Figure 8). Given that a problem with incompatible versions is solved by means of isolation, it’s possible to migrate all of the existing Spark projects to Mesos without upgrading all of them and keep running different versions of Spark and Java which are currently in use.
It’s worth mentioning that JobServer is running on the same cluster with the same fault tolerance and high availability guarantees provided by Mesos and Marathon. Another important aspect of installations running on any kind of orchestration platform is physical node characteristics and cluster layout which takes those aspects into account. This topic will be covered in the next part of the series together with migration of JobServer to Marathon and using Docker as a main tool for packaging and distribution of the applications running on Mesos.